
In the current context in which we live the increasing generation and use of data has posed complex challenges to organisations. And the diversity and quantity of existing data are increasing, leading to the need to implement a robust data strategy, and repositories capable of storing and dealing with this data – the Data Lakes. Although the existence of this new data ecosystem brings unquestionable benefits to organisations, it is necessary to imagine and plan a set of factors behind data governance and processes where data consistency and integrity and the need for standardisation, as well as confidentiality and data security issues, stands out, and all these issues must be considered by the design of the architecture and frameworks to be implemented.
This first article focuses on the data capture and ingestion component, as this is the first challenge that arises from adopting a new data strategy.
Data Ingestion
In a less future-proof and immediatist approach, there might be the temptation to consider an ingestion framework as the heterogeneous use of parts that facilitate the implementation of diverse pipelines. However, this approach leads to scenarios where, potentially, each ingestion will be treated as a separate pipeline, something that leads to an environment that is increasingly difficult to maintain, manage and evolve. This is because there is no guarantee of reusing ingestion principles (e.g. output formats, ingestion meta-information, checks, ingestion method and information consolidation, global information flow) nor a way to obtain a more consolidated view of all configured ingestion pipelines.
Valuing these principles, Xpand IT has worked, for several years, on these aspects, i.e. the development of ingestion frameworks, where the basic principle is technologically agnostic, thus intensively leveraging the infrastructure pieces available in each client, allowing standardisation of the critical phase of data acquisition for the platform. These frameworks, despite being, in concept, a development component, are based on the principle of leveraging existing infrastructure pieces, reducing the need for specific developments whenever possible.
The following scheme represents a typical architecture for an ingestion framework:
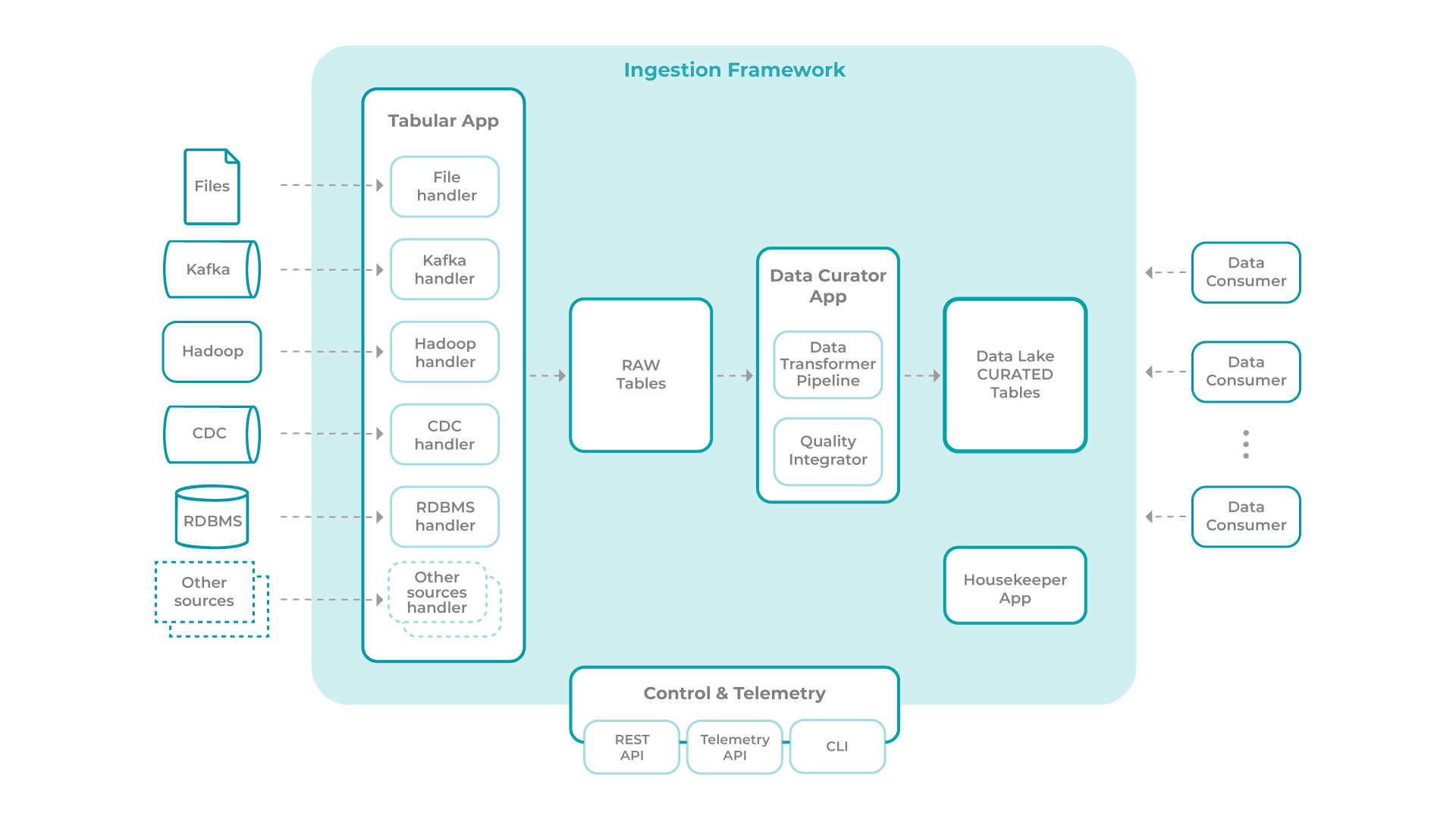
This framework is composed of the following main modules:
? Tabular Ingestion App
? Data Curator App
? Housekeeper App
? Control & Telemetry
Tabular Ingestion App
This represents the boundary between the external information systems, where the data comes from, and the Data Lake, where the Ingestion Framework operates. All the data ingested by the framework, regardless of the source, will have to be transformed into a tabular format before they can move on to the following phases. As a general rule, it is suggested that dumps of the source data exist in some format before being transformed into a tabular format. This last case will be useful as a backup, for instance, of clickstream events coming from an event broker, in order to guarantee not only their retention but also their recoverability in case any problem is identified in the process of converting these events to tabular format. This space constitutes a Raw Zone. This application encloses a modular logic, where new types of sources can be added with the inclusion of new modules/handlers, thus allowing the extension of its application.
Data Curator App
Once in a tabular format, all tables undergo a set of validations and possible enrichment, carried out by the Data Curator App, with a view to consolidating them and making them available in the target work area. The most significant part of this component and task is guaranteed by the Data Transformer Pipeline, and it is possible to develop several transformation rules (e.g. applying hashing on a column).
This module also has a “Quality Integrator” feature, which allows the incorporation of quality rules without resorting to external tools, whether they are of a simpler nature, dependent on the contents of the line to be ingested (e.g. validation of the XXXX-XXX postcode) or of a more complex nature (e.g. comparison of the average value of a column in a temporal range with its homologous one). These can be complemented with the validation of access policies which, using a data catalogue tool, makes it possible to validate whether the tables that are about to be made available for consumption are duly registered in the catalogue and have defined access policies.
At the end of the curating process, the tables are made available ready to be consumed.
Housekeeper App
This application is intended to handle the retention of ingested data. Each table will have a column that indicates the ingestion date of a record. For each table, it is defined in the data catalogue which retention, creating a rule that uses the referred control column. The Framework also internally manages the set of raw tables. The retention rules for these tables are configured directly in the “Control & Telemetry” module.
As a rule, this application is triggered in batch, usually daily, and on start-up, it checks the tables eligible for the housekeeping process and triggers the process of eliminating expired records.
The potential inclusion of GDPR-related requirements makes this module important in that it empowers the framework to manage the entire data lifecycle, demonstrating the evolvability and future-proofness of the presented framework.
Control & Telemetry
The ingestion of a given data source and transformation to its curated version is characterised by a set of steps. For example, to ingest events from a message broker it is necessary to indicate:
(1) the source;
(2) which meta-information (i.e. schema) of the source data;
(3) the read cadence;
(4) and which transformations to apply, such as enrichments, data cleansing, etc.
These steps define an ingestion flow.
The configuration of the various steps of an ingestion flow, which has a direct effect on the orchestration of the ingestion, is performed in this “Control & Telemetry” module, programmatically leveraging the pipeline orchestrator, something that allows not only leveraging the available platform but also reducing the development effort.
The configurations of this component are, in general, stored in an auxiliary “database”, and can be defined and accessed through an API. This API will also be used by the various applications of the framework to report on the execution status of the various stages of ingestion, thus constituting the “Telemetry API”.
Final Thoughts
The adoption and use of such an ingestion framework enable:
? A highly scalable platform, with the ability to add new data sources without having to work separate pipelines;
? A versatile platform, in that its modules, external connectors and information consumers are technologically agnostic, allowing the customer to choose their desired technological platform.
? An enterprise-grade framework, meeting data governance criteria.









