
Data Science Hands-on: “Predicting movies’ worldwide revenue”
On May 4th, a day known worldwide as Star Wars Day (“May the fourth“), approximately 40 Data Science fans seized this occasion to learn more about this subject by practicing and sharing on yet another Lisbon Kaggle Meetup. The “Data Science Hands-on” Meetup took place at Instituto Superior Técnico (IST Campus) and it was precisely dedicated to cinema:
- the problem addressed consisted in predicting movies’ revenue before their premiere!
This event was also sponsored by Xpand IT, in collaboration with Hackerschool Lisboa, a group of IST students interested in technology, who also evangelizes the practice of learn-by-doing.
First off, the event started with a presentation by Xpand IT’s own Ricardo Pires, who introduced the company and their units focused on data treatment and exploration. Participants received a sample of how these problems fit in a real-world context. Shortly after, professor Rui Henriques, who teaches Data Science at IST, explained his perspective on how to approach a Data Science problem, providing some tips related to the meetup’s challenge.
Data from this challenge leverage learning and provide an idea of a potentially real problem, as they are semi-structured and demand a great amount of effort to process.
An estimated 80% of Data Scientists’ daily work revolves around data treatment.
(Source: Forbes)
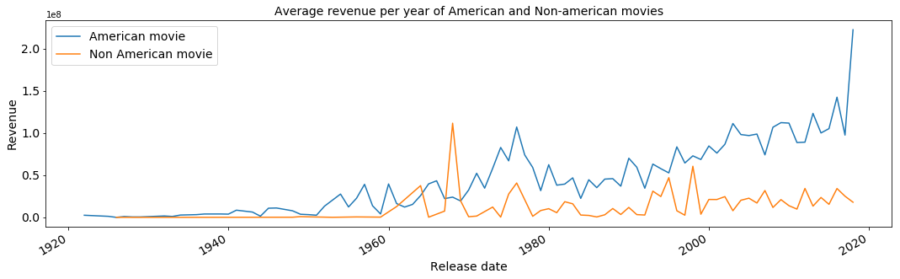
After the two presentations, participants started to unravel the mysteries hidden within the data. They verified, for example, a generalized increase in revenue over the years. They also noticed that American movies had a superior revenue, compared to all the rest.
Tackling the challenge
On the first part, participants modelled the problem with simpler columns, structured as:
- budget
- popularity
- runtime
- data
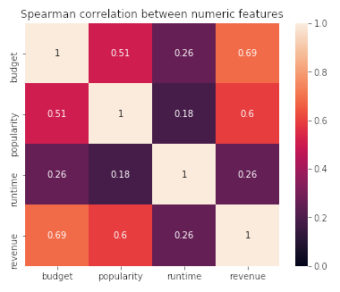
By doing so, they’ve tried to obtain the first predictions for the movies’ revenue. On the image below, which represents Spearman’s rank correlation coefficient, we can verify that budget and popularity columns are the most correlated with revenue.
During the second phase, contestants tackled the semi-structured columns, applying the one-hot encoding technique, as:
- director
- cast
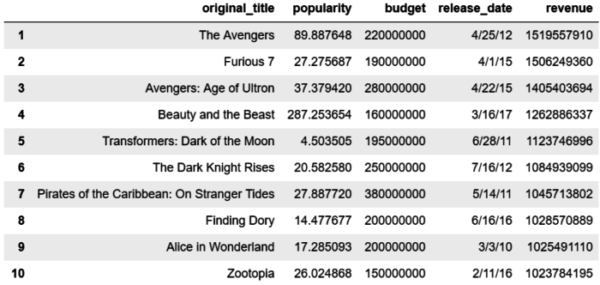
Through this deeper analysis of the data, teams found out that the movies that generated more revenue (see table below).
Other relevant aspect to consider is that popularity is not always directly related with revenue, such is the case with “Transformers: Dark of the Moon”, as it is represented as less popular, but with a high revenue nonetheless.
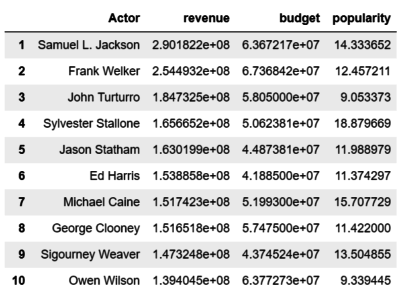
It is also interesting to observe the actors who generated more revenue on average:
Conclusions
At the end of the meetup, participants shared their implemented solutions:
- The group with the best results applied Logistic Regression. Despite being a simple model, it can provide adequate results when the focus is data treatment.
- Data treatment went through several techniques, such as detection of outliers, in movies with a very discrepant budget, replacing these values with the median.
- Budget and revenue columns were transformed into their respective logarithm, in order to approximate them to a Gaussian distribution.
- One of the advantages of using a simpler model is that these are also easier to explain to a business stakeholder.
The fourth of May was spent learning alongside the most wonderful people, enlightening in every way. In case you’re interested in Data Science, join the community and show up at our monthly events.
More information on the “Data Science Hands-on” Meetup.

Joana Pinto
Data Scientist, Xpand IT

Alexandre Gomes
Data Scientist, Xpand IT















