
Qual a importância da portabilidade? O mundo em que hoje vivemos pauta-se por um desenvolvimento tecnológico veloz, facto que se traduz numa enorme quantidade de tecnologias que nos permitem armazenar, transformar e consultar dados. Dependendo da estratégia interna da sua empresa, poderá decidir manter toda a infraestrutura tecnológica on-premise, tendo sempre em conta os custos de manutenção e operação, ou poderá optar por uma solução mais simples, passando a utilizar serviços cloud e escolhendo, para este efeito, um ou mais fornecedores destes serviços. É precisamente aqui que o problema começa.
Tipicamente, uma das perguntas que recebemos dos nosso clientes é: será que a escolha do fornecedor de serviços cloud interessa? Como bons consultores a resposta tende a ser “depende”. A estrutura de custos é diferente, as interfaces e API’s para desenvolvimento de aplicações são igualmente diferentes e, mais importante ainda, as ferramentas disponíveis e a sua maturidade também variam de fornecedor para fornecedor. Seleccionar um fonecedor de cloud termina, normalmente, num compromisso entre custo e tecnologia.
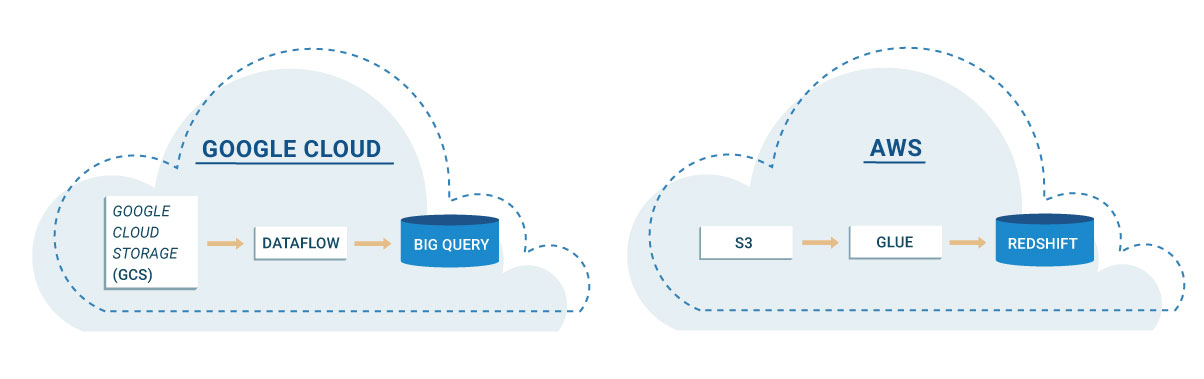
Relativamente aos processos de ETL, normalmente é necessária tecnologia que permita ler e transcrever os dados, outra que possa codificar os processos e uma API através da qual se possa consultar os dados ou torná-los disponíveis para consumidores externos (por exemplo, numa base de dados ou similar). Todos os fornecedores cloud disponibilizam opções para as ações acima mencionadas, utilizando alguns dos serviços da Google Cloud Platform (GCP) e da Amazon Web Services (AWS) como exemplo:
- Google Cloud Storage + Google Dataflow + Google BiqQuery
- S3 + Glue + Redshift
Todas estas tecnologias têm pontos fracos e pontos fortes, mas executam a função para o qual foram desenhadas de um modo exemplar. Mas e o que acontece se implementar todos os seus processos de ETL utilizando estas ferramentas e, posteriormente, decidir abandonar a estratégia cloud ou até mudar de fornecedor?
Portabilidade vs. Performance (E como pode afetar a dependência com o fornecedor cloud)
Nem sempre é necessário existir portabilidade (e eu concordo com isso). Aliás, este blog post pode até nem fazer sentido para si caso tenha a certeza de que a sua operação irá estar associada apenas a um forncedor de cloud. Por norma, as grandes organizações que operam em vários países regulados apresentam um problema – do qual não se fala com frequência – que é o facto de nem todos os fornecedores de serviços cloud poderem assegurar as suas operações em todos os países do mundo (pensem, por exemplo, em instituições financeiras que necessitam de processar/transformar dados em países regulados mas de onde os dados não podem sair) e, da nossa experiência de campo, normalmente existem dois cenários para estes processos:
- Os processos de carregamento e transformação são muito simples e operam sob conjuntos de dados pequenos/moderados (vamos assumir para este exemplo uma escala de magnitude de altos valores de megabytes a baixos valores de gigabytes), para os quais não é necessário utilizar tecnologias de computacão elástica. Estes casos normalmente representam 60 a 85% dos casos de uso;
- Os processos de carregamento e de transformação são muito complexos e operam sob conjuntos de dados muito grandes (que variam entre altos valores de gigabytes e valores superiores) e que necessitam de tecnologia que consiga escalar o suficiente para atingir o nível necessário, de modo a fazer a computação em tempo adequado. Estes são normalmente os restantes casos, representando entre 15 a 40%.
O primeiro cenário, felizmente, é o mais comum. O facto de a maior parte dos processos de ETL serem “simples” significa que, talvez, seja possível evitar o uso de tecnologias de armazenamento de dados e/ou computação que rapidamente o tornem dependente do fornecedor cloud. O segundo cenário é ligeiramente mais complexo mas mais interessante.
Num cenário em que se revela necessário que a tecnologia escale de acordo com a quantidade de dados para processar, faz com que, normalmente, seja preciso tomar algumas decisões e fazer alguns compromissos tecnológicos. Hoje em dia, felizmente, já existe um espectro considerável de ferramentas que permitem escalar o processamento e os fornecedores cloud optam por focar-se apenas num pequeno conjunto que possibilitam a manutenção dos utilizadores. Por exemplo, no GCP existe o DataFlow, DataProc e BigQuery para processar dados, enquanto que em AWS se poderá considerar Athena, EMR e Redshift, entre outros.
Independentemente da selecção das ferramentas ou do fornecedor cloud irá sempre existir uma necessidade de orquestrar estes processos, de modo a implementar processos de ETL. É aqui que uma ferramenta como o Pentaho Data Integration pode ajudar, independentemente da escolha tecnológica.
Como pode uma ferramenta como o Pentaho Data Integration ajudar?
Para os menos atentos, o Pentaho Data Integration (PDI) da Hitachi Vantara é uma ferramenta de ETL open source, que pode ser utilizada para implementar os processos de ETL. O PDI pode, ainda, ajudar com a execução em cloud e com a orquestração de processos através de algumas das suas funcionalidades, já que:
- Tem o seu próprio motor de transformação, que pode ser usado independentemente do fornecedor de cloud;
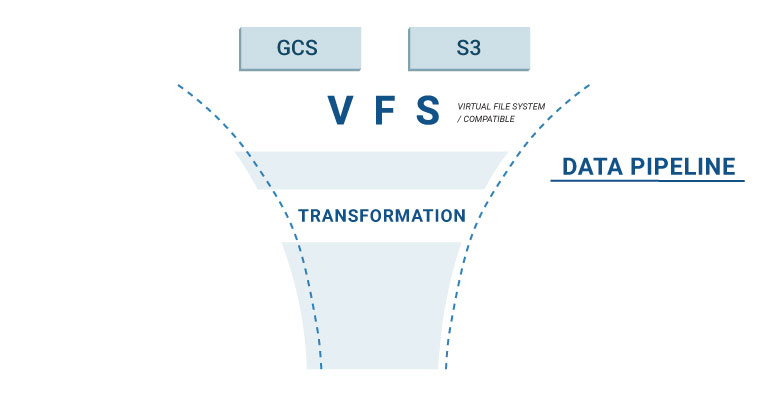
- Consegue abstrair a camada de armazenamento de dados utilizando um conceito de Sistema de Ficheiros Virtual (VFS);
Consegue interagir com tecnologias externas, como por exemplo, o Google BigQuery ou Redshift, para orquestrar processos que dependem de outras tecnologias.
Então, como tornar isto possível?
Abstrair a camada de armazenamento de dados
O PDI oferece uma funcionalidade VFS muito útil, implementada com base no projeto Apache VFS, que possibilita a abstração dos sistemas de ficheiros. Na prática, o que isto significa é que idependentemente dos processos requererem uma leitura e/ou escrita num sistema de ficheiros, é possível implementá-los sem ter de pensar que tipo de sistema de ficheiros está a ser utilizado, já que pode ser um sistema local, um servidor SFTP remoto, Google Cloud Storage ou, até, S3. Assim, as transformações de ETL implementadas de um modo correto irão funcionar de maneira transparente sobre todos eles. Mas como é que isto funciona?
É muito fácil! A notação do sistema VFS necessita de um prefixo para o filesystem, que ajuda a identificar um caminho para um ficheiro, tal como:
filesystem://path/to/file.txt
O que isto quer dizer é que se nos processos de ETL quiser aceder a um caminho denominado “/input-data/sales/” poderá utilizar esta funcionalidade para exprimir esse caminho da seguinte forma:
file:///input-data/sales/
s3://bucket-name/input-data/sales/
gs://bucket-name/input-data/sales/
Resumidamente, o que isto indica é que é possível escrever código que opera sobre um sistema de ficheiros independentemente do seu tipo. Mas que mais podemos utilizar para manter o nível de portabilidade?
Um motor de ETL independente
Como indicado anteriormente, o PDI possui o seu próprio motor de execução e, como é baseado na linguagem de programação Java, pode ser executado em todos os ambientes nos quais a máquina virtual Java seja compatível. Quer isto dizer que ao implementar processos de ETL implementados com o PDI já não é necessário pensar na tecnologia que o irá executar, característica que o torna altamente fléxivel para poder ser executado em diferentes ambientes. Poderá codificar apenas uma vez e instalá-lo onde quer que o motor execute.
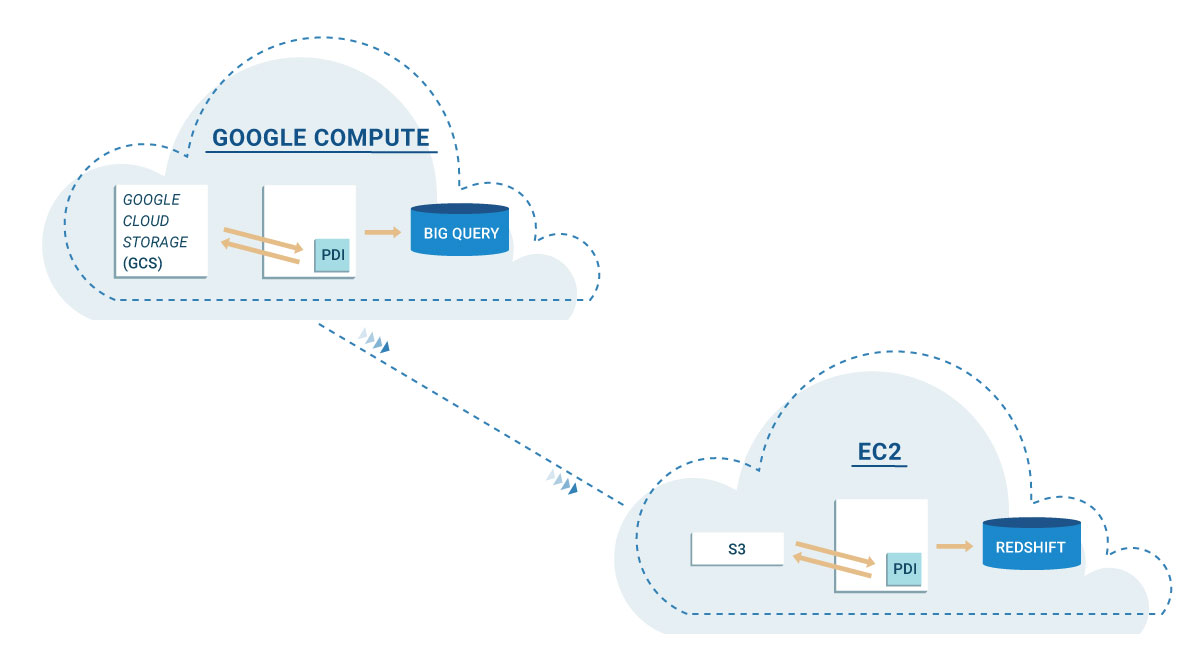
O que isto quer dizer, voltando ao tópico do artigo, é que para os processos de ETL simples que definimos anteriormente, poderá atingir um nível de portabilidade muito alto com o PDI que, por sua vez, irá permitir mover o ETL de ambiente de uma maneira muito simples. Por exemplo:
- Comece por desenhar e testar os processos de ETL nos seus servidores e sistema de ficheiros locais, nos quais o PDI é executado, seja numa máquina virtual ou num servidor utilizado para o efeito;
- Decida se pretende mover o ETL para AWS e parametrize o ETL de modo a que seja usado o AWS S3 como sistema de ficheiros, em vez do seu sistema de ficheiros local, e instale o PDI numa instância EC2;
- Por motivos externos, é necessário que esse mesmo ETL passe a utilizar a Google Cloud Platform para que se possa executar este processo em diferentes regiões do planeta: parametrize o ETL de modo a que possa utilizar o Google Cloud Storage como sistema de ficheiros e instale o PDI num instância de Google Compute;
É claro que esta é uma visão muito limitada sobre aquilo que se pode fazer através de um fornecedor cloud, no entanto, dá-lhe a possibilidade de ter 100% de portabilidade e uma facilidade de migração do ETL, sem a qual não seria possível. Para cenários mais complexos, o PDI também tem algumas opções que permitem escalar o processamento ou ligar-se a ferramentas externas:
- É possível utilizar um ou mais servidores Carte embebidos para escalar a solução horizontalmente, seja para dividir ou para segmentar o processamento;
- É possível implementar as transformações de dados em Map/Reduce nativo;
- É possível utilizar a nova Abstract Execution Layer para escalar o processamento utilizando a framework Apache Spark;
- É possível ligar a ferramentas externas como Google BigQuery ou Redshift depois de carregados os dados para orquestrar todo o processamento.
A estes cenários mais complexos acrescenta-se o facto de que é necessário orquestrar os processos de ETL, na maioria das vezes, de um modo mais simples, para que não se torne a manutenção da solução demasiado complexa.
Orquestrar o processamento de dados
Ao longo deste artigo abordámos dois cenários de processamento. No entanto, estes dois cenários vivem em conjunto, de modo a que se possam formar os processos de ETL completos numa empresa. Num cenário em que seja necessária alguma portabilidade entre fornecedores cloud, é fundamental que tenha à sua disposição uma ferramenta altamente fléxivel e parameterizável, de modo a adaptar-se de uma forma mais dinâmica aos requisitos de execução.
Por exemplo, se tiver uma implementação em AWS que utiliza S3 e Redshift e quiser mover para GCP:
- O código que manipula ficheiros e processamentos e que apenas utiliza S3, poderá ser transportado a 100% para GCS, quando implementado utilizando as capacidades de VFS do PDI;
- O código que carrega e orquestra os processos externos em Redshift, provavelmente não terá a portabilidade assegurada na sua totalidade (isto é, se conseguir garantir alguma…) mas pode ser implementado de modo a que seja possível trocá-lo por uma implementação compatível com Google BigQuery, que utiliza os mesmos ficheiros de input e estrutura de tabelas, para que possa ter um funcionamento compatível.
Claro que este facto requer que sejam mantidos módulos de código específicos para cada fornecedor cloud mas, pelo menos, é possível compartimentalizar e encapsular esta funcionalidade de uma maneira mais simples, para que se possa proceder a uma alteração, se necessário. Com o PDI, a funcionalidade de orquestração, nomeadamente Jobs, permite parameterizar configurações para a própria orquestração, que, por sua vez, permite trocar estes módulos de um modo extremamente simples.
Conclusão
Espero que este artigo tenha sido esclarecedor de como é possível implementar os seus processos de ETL e ainda manter alguma portabilidade entre fornecedores cloud. Ferramentas como o PDI tornam muito mais simples atingir este objetivo, sabendo que as versões futuras da ferramenta irão facilitar o alcance a um maior nível de portabilidade, através de algumas novas funcionalidades!













