
No contexto atual em que vivemos a crescente geração e utilização de dados tem colocado desafios complexos às organizações. E é cada vez mais a diversidade e quantidade de dados existente que leva à necessidade de implementar uma estratégia de dados robusta, e à implementação de repositórios capazes de armazenar e lidar com estes dados – os Data Lakes. Apesar da existência deste novo ecossistema de dados trazer benefícios inquestionáveis às organizações, é necessário planear e prever um conjunto de fatores no governance de dados e processos onde se destacam a consistência e integridade dos dados, a necessidade de normalização, bem como questões de confidencialidade e segurança, sendo que todos estes temas devem estar previstos no desenho da arquitetura e frameworks a implementar.
Este primeiro artigo foca-se na componente de captura e ingestão de dados, já que este é um dos primeiros desafios na estratégia de dados que podemos encontrar na sua adoção.
A Ingestão de Dados
Numa abordagem menos future-proof e imediatista, poderá haver a tentação de considerar uma framework de ingestão como a utilização heterogénea de peças que facilitam a implementação de pipelines diversos. No entanto, esta abordagem conduz a cenários onde, potencialmente, cada ingestão venha a ser tratada como um pipeline separado, algo que leva a um ambiente cada vez mais difícil de manter, gerir e evoluir. Tal sucede pelo facto de não haver uma garantia de reutilização de princípios de ingestão (por exemplo: formatos de saída, meta-informação da ingestão, verificações, método de ingestão e consolidação de informação, fluxo global da informação) nem uma forma de ter uma visão mais consolidada de todas os pipelines de ingestão configurados.
Valorizando estes princípios, a Xpand IT,de forma a mitigar os desafios na estratégia de dados, tem trabalhado, desde há vários anos, estas vertentes no desenvolvimento de frameworks de ingestão, cujo princípio base é agnóstico da tecnologia, não deixando, assim, de alavancar intensivamente as peças infraestruturais disponíveis em cada cliente, permitindo standardizar esta fase tão crítica de aquisição de dados para a plataforma. Estas frameworks, não obstante serem, em conceito, um componente de desenvolvimento, têm como princípio o aproveitamento das peças infraestruturais existentes, reduzindo a necessidade de desenvolvimentos específicos sempre que possível.
O esquema seguinte representa uma arquitetura tipo para uma framework de ingestão:
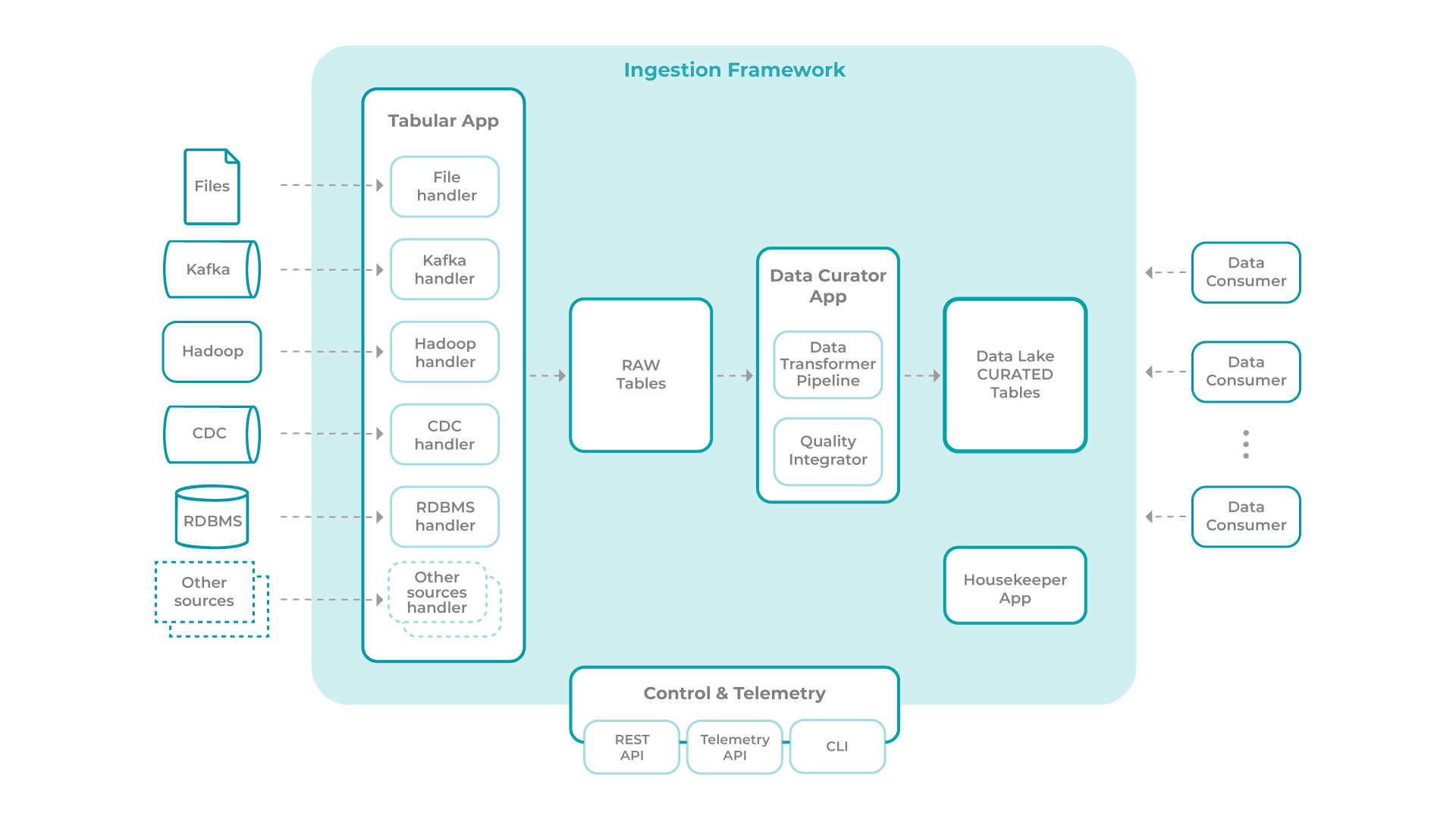
Esta framework é composta pelos seguintes módulos principais:
? Tabular Ingestion App
? Data Curator App
? Housekeeper App
? Control & Telemetry
Tabular Ingestion App
Representa a fronteira entre os sistemas de informação externos, de onde os dados provêm, e o Data Lake, onde atua a Framework de Ingestão. Todos os dados ingeridos pela framework, independentemente da fonte, terão de ser transformados num formato tabular antes de poderem passar para as fases seguintes. Regra geral, sugere-se que existam dumps das fontes de origem num qualquer formato antes destes serem transformados num formato tabular. Este último caso será útil como backup, por exemplo, de eventos de clickstream provenientes de um broker de eventos, de modo a garantir não só a retenção destes, como a possibilidade de recuperação, caso seja identificado algum problema no processo de conversão destes eventos para formato tabular. Este espaço constitui uma Raw Zone. Esta aplicação encerra uma lógica modular, onde novos tipos de fontes podem ser adicionados com a inclusão de novos módulos/handlers, permitindo assim a extensão da sua aplicação.
Data Curator App
Uma vez num formato tabular, todas as tabelas passam por um conjunto de validações e possível enriquecimento levado a cabo pelo Data Curator App, com vista à sua consolidação e disponibilização em área de trabalho de alvo. A parte mais significativa deste componente e tarefa é garantida pela Data Transformer Pipeline, sendo possível o desenvolvimento de várias regras de transformação (exemplo: aplicação de hashing sobre coluna).
Este módulo disponibiliza, ainda, um módulo “Quality Integrator”, que permite a incorporação de regras de qualidade sem recurso a ferramentas externas, sejam elas de carácter mais simples, dependentes do conteúdo da linha a ser ingerida (e.g. validação de código-postal XXXX-XX) ou de carácter mais complexos (e.g. comparação de valor de média de coluna em range temporal com homólogo) podendo as mesmas ser complementadas com validação de políticas de acesso que, fazendo uso de uma ferramenta de catálogo de dados, permite validar que as tabelas que estão prestes a ser disponibilizadas para consumo estão devidamente registadas no catálogo e que possuem políticas de acesso definidas.
No final do processo de curating são disponibilizadas as tabelas prontas a serem consumidas.
Housekeeper App
Esta aplicação tem como finalidade lidar com a retenção dos dados ingeridos. Cada tabela terá uma coluna que indica a data de ingestão de um registo. Para cada tabela, é definido no catálogo de dados qual a retenção, criando uma regra que use a coluna de controlo referida. A framework gere também, internamente, o conjunto de tabelas raw. As regras de retenção dessas tabelas são configuradas diretamente no módulo de “Control & Telemetry”.
Por norma, esta aplicação é despoletada em batch, tendencialmente diário, sendo que, no arranque verifica as tabelas elegíveis ao processo de housekeeping e despoleta o seu processo de eliminação de registos expirados.
A potencial inclusão de requisitos relacionados com GDPR fazem com que este módulo seja importante na medida em que capacita a framework na gestão de todo o ciclo de vida dos dados, mostrando assim a capacidade de evolução e future-proofness da framework apresentada.
Control & Telemetry
A ingestão de uma dada fonte de dados até à sua versão curated é caracterizada por um conjunto de etapas. Por exemplo, para ingerir eventos de um broker de mensagens é necessário indicar:
(1) a origem;
(2) qual a meta-informação (exemplo: schema) dos dados origem;
(3) a cadência de leitura;
(4) e quais as transformações a aplicar, tais como enriquecimentos, data cleansing, etc.
Estas etapas definem um fluxo de ingestão.
A configuração dos vários passos de um fluxo de ingestão que, tem efeito direto na orquestração da ingestão, é realizado neste módulo de “Control & Telemetry”, alavancando programaticamente o orquestrador dos pipelines, algo que permite não só alavancar a plataforma disponível, como reduzir o esforço de desenvolvimento.
As configurações deste componente são, regra geral, armazenadas numa “base de dados” auxiliar, podendo ser definidas e acedidas através de uma API. Esta API será também usada pelas diversas aplicações da framework para reporte do estado de execução das várias etapas de ingestão, constituindo assim a “Telemetry API”.
Pensamentos Finais
A adoção e utilização de uma framework de ingestão deste tipo, numa nova estratégia de dados, permite:
? Ter uma plataforma altamente escalável, com a possibilidade de adicionar novas fontes de dados sem necessidade de trabalhar pipelines separadas;
? Plataforma versátil, na medida em que os seus módulos, conectores externos e consumidores de informação são agnósticos da tecnologia, permitindo ao cliente ter escolha sobre a plataforma tecnológica pretendida;
? Framework Enterprise-Grade, cumprindo critérios de governance de dados.
Desta forma, conseguimos mitigar os desafios na estratégia de dados e garantir sucesso na sua adoção.










