5 SECONDS-SUMMARY:
- dbt represents a paradigm shift in the way organisations approach data transformation;
- In this article, you will learn what dbt is, what dbt does for data, the difference between dbt Core and dbt Cloud, and all the benefits of starting to use it immediately.
In today’s data-driven world, businesses constantly seek innovative solutions to streamline their data workflows and extract valuable insights. Enter dbt – a revolutionary technology that has been gaining traction among data professionals for its ability to transform the way organisations manage and leverage their data.
dbt represents a paradigm shift in the way organisations approach data transformation, offering a modern, collaborative, efficient solution for managing data pipelines. Whether you opt for a cloud solution with a managed platform or deploy dbt in an on-premises solution for greater control, embracing dbt can undoubtedly drive value and accelerate data-driven decision-making for your business.
What dbt does for data
dbt, short for data build tool, is an open-source command-line tool that enables data analysts and engineers to transform data in their warehouses more effectively. It focuses mainly on the T (Transformation) of the ETL or ELT process, designed to work on data after it has been loaded. The main characteristic of this tool is the combination of Jinja templates with SQL and reusable models.
The tool also provides several features that make it easier to work with data. These features include the ability to manage dependencies between data models, run tests to ensure data integrity and track the lineage of data to understand how it has been transformed over time.
Why should you use dbt
1. Simplicity, modularity and reusable code: With its SQL-based approach, dbt simplifies the data transformation process, making it accessible to users with different levels of technical expertise. Besides that, dbt promotes modularisation, allowing users to break down complex transformations into smaller, reusable components, enhancing maintainability and scalability.

Example of a simple dbt model

dbt allows you to use macros to reuse code
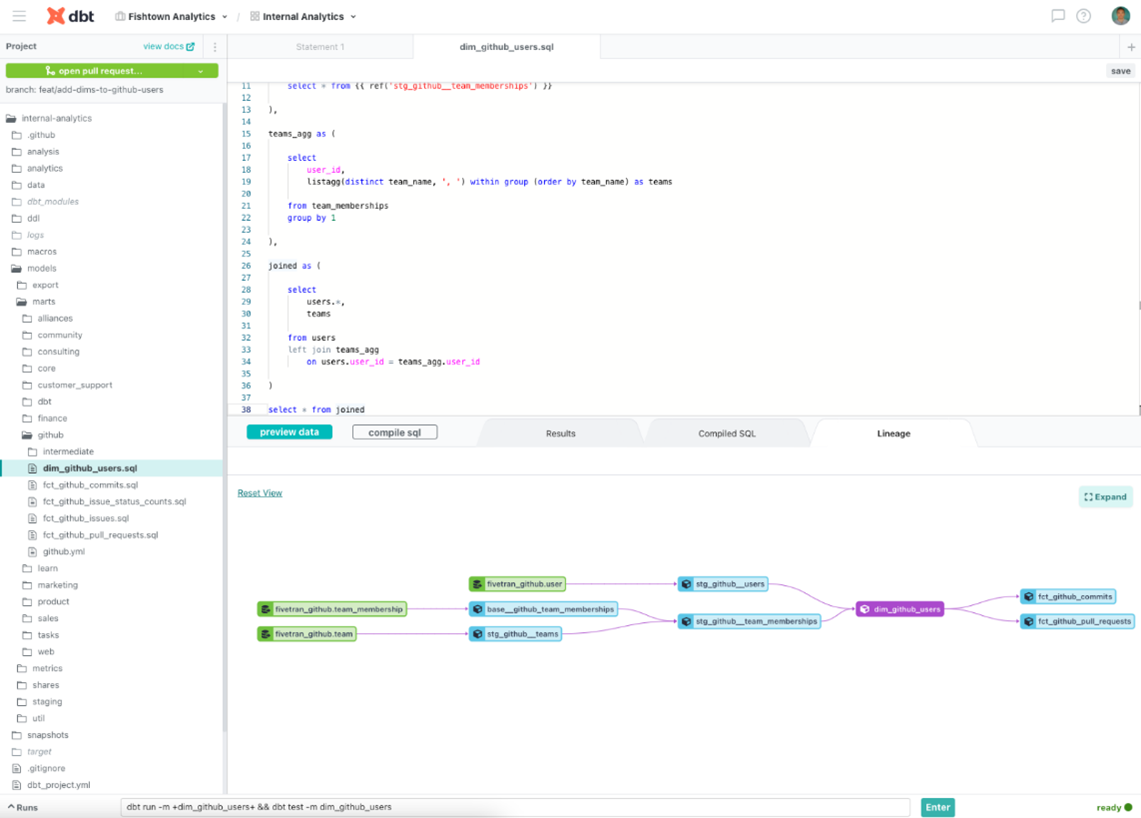
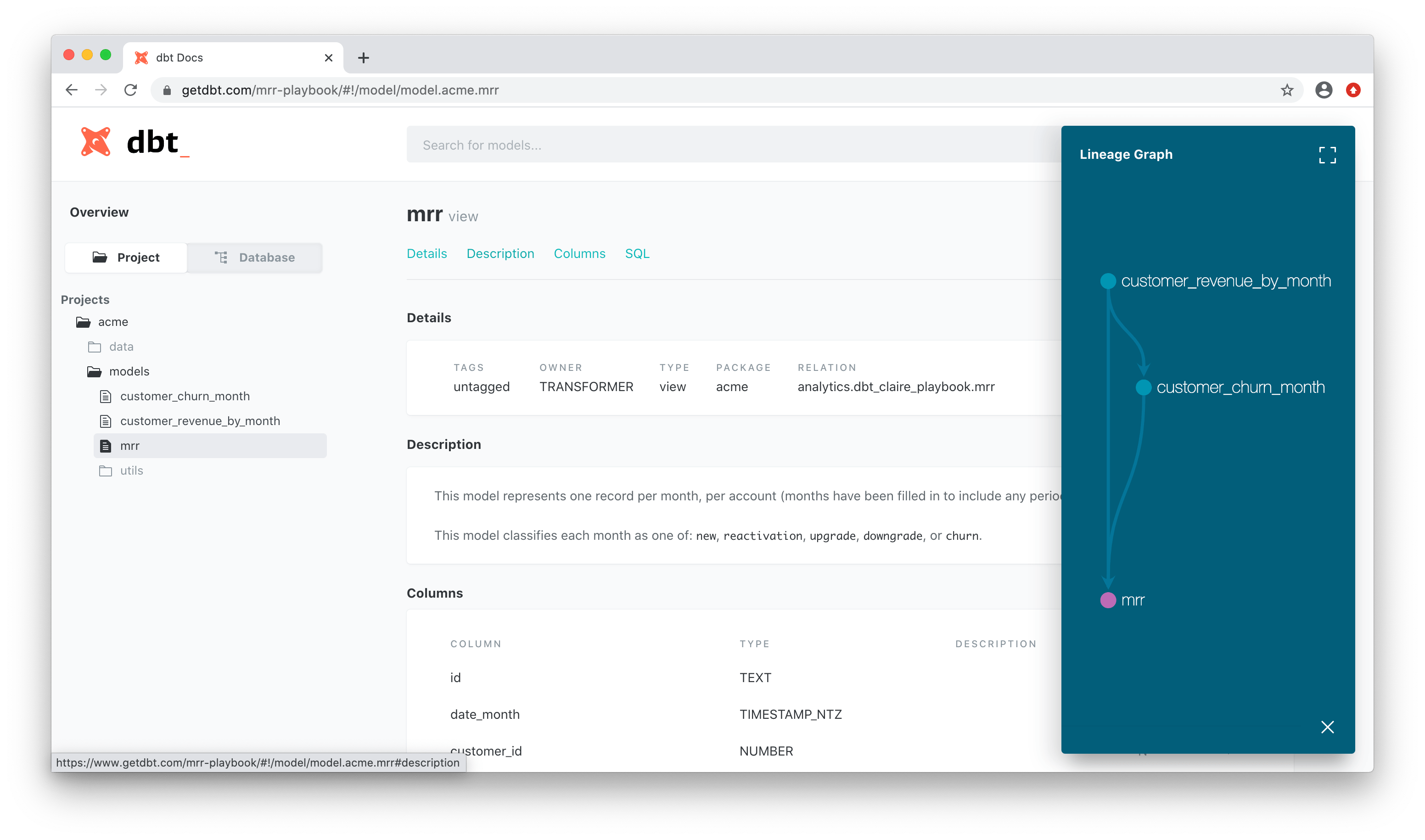
2. User-friendly UI: The simple, intuitive interface allows teams to work collaboratively by leveraging version control systems like Git, to track changes to their data transformation code. It also automatically generates documentation for your data models. This documentation includes text and graphic information about the data sources, transformations and any tests associated with the model.
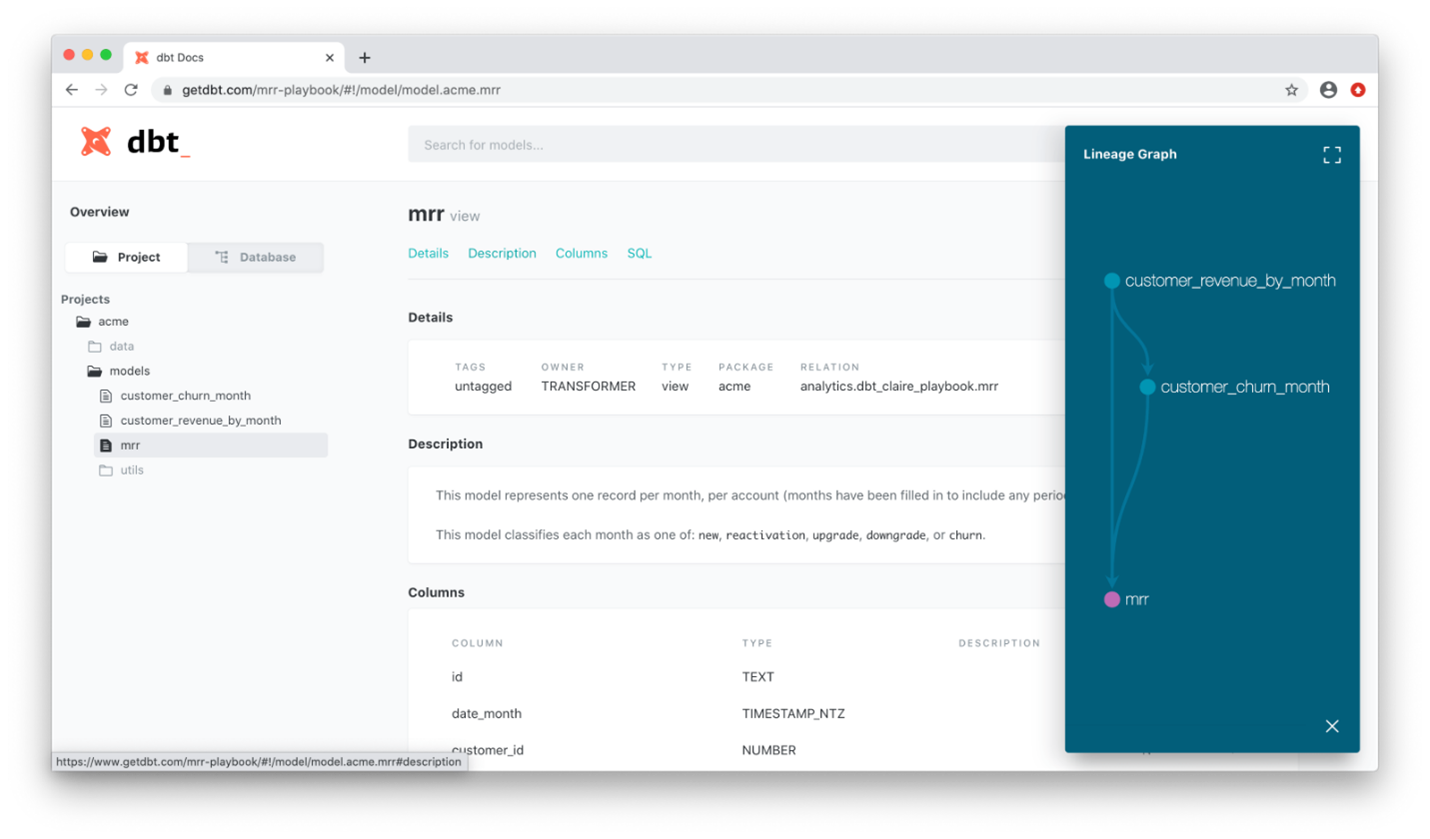
dbt Cloud UI documentation page. Source.
- Testing: dbt includes a testing framework that allows you to define and run tests on your data models. This ensures the integrity and quality of your data, helping catch issues early in the pipeline.

Example of how generic tests are implemented in .yml files
4. Automation and integration with data sources: With dbt, users can automate their data transformation workflows, reducing manual effort and accelerating the time-to-insight. Besides that, dbt seamlessly integrates with various data sources and warehouses, including Snowflake, BigQuery, Redshift and more, enabling users to leverage their existing infrastructure.
5. Community support: dbt boasts a vibrant community of users and contributors who actively share best practices, contribute to the development of additional packages and provide support through forums and Slack channels.
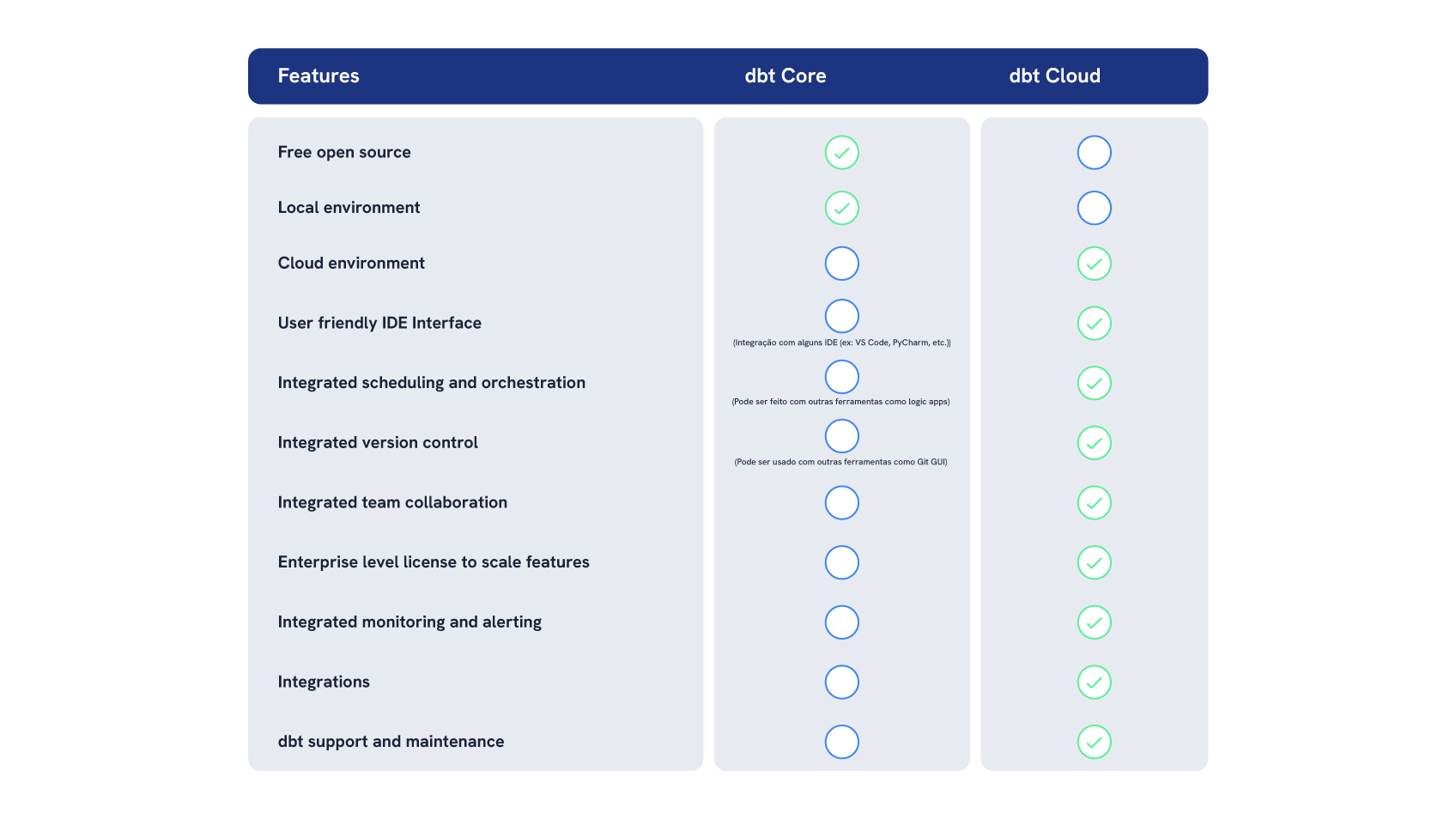
dbt Core vs dbt Cloud
Once you decide that dbt is right for your organisation, the next step is to determine how you’ll access dbt. The two most prevalent methods are a free version called dbt Core, which you can implement locally, and a paid version called dbt Cloud, where you can enjoy a full cloud solution. Understanding the differences is important for choosing the right tool to meet your specific data transformation needs. While with dbt Core you have your solution locally, you’ll need to reconcile various capabilities with other tools. With dbt Cloud, you’ll have all features and capabilities centralised.
Final Thoughts
It’s crucial to recognise that dbt is only part of a well-defined data strategy. Achieving optimal data utilisation is challenging, encompassing complexities while assembling the team with the right skills, selecting appropriate tools and determining relevant metrics. Even with these resources, organisations may still struggle to leverage data effectively.
While recommending dbt it’s essential to emphasise the importance of a robust underlying infrastructure comprising skilled teams, suitable tools and efficient processes for data success. And if you don’t know where to start and how to build a powerful foundation for data success, we can help you.
Ready to unlock the full potential of your data? Start your dbt journey today!


















{kind=link}
{kind=link}