
Why portability matters? In this ever fast developing technological world there are an overwhelming amount of technologies that can be used for storing, transforming and querying your data. Depending on your internal strategy, you might either decide to keep all your infrastructure on-premise coping with the maintenance costs or opt for a more streamlined solution to embrace the cloud and select one (or more) cloud provider to host your IT needs. The quest starts here.
Typically one of the questions we get from our customers is: does cloud provider selection matter? As any good consultant, our answer is usually „it depends“. Costs are different, the interfaces and API’s are different, and more importantly, the available toolsets and related maturity are also different. Selecting a cloud provider will usually end up in a compromise between cost and technology.
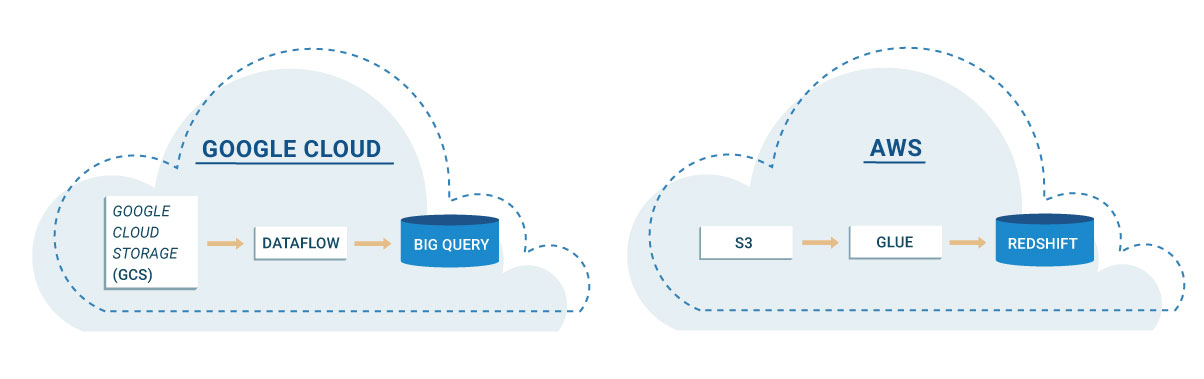
Now, specifically for ETL-type workloads, you usually need one or more places to read and write your data to, a piece of technology where you can code your data pipelines and an API where you can query and/or make your data available to other external consumers (e.g. a database or similar). Cloud providers offer all of the above; using some of the tools available on Google Cloud Platform (GCP) and Amazon Web Services (AWS) as examples:
- GCP: Google Cloud Storage + Google Dataflow + Google BiqQuery
- AWS: S3 + Glue + Redshift
All these technologies have their strengths and weaknesses, and they do what they are intended to do very well, but what happens if you implement your whole ETL pipeline using these tools and then decide to either move away from the cloud or swap provider?
Portability vs. Performance (and how it affects vendor lock-in)
One can argue that there is not always a need for portability, and that is very true. This whole blog post might not even make sense if you’re sure that you’re going to stay strictly within the remit of a single cloud provider. However, larger enterprises that operate in a multitude of countries typically face the challenge that a single cloud provider doesn’t operate in all the countries required (think banks or financial institutions that need to load/transform data in regulated countries where the data cannot leave the host country). From our experience implementing ETL projects, there are usually two main scenarios (which are actually not mutually exclusive):
- The ETL pipelines are very simple and operate over moderately sized datasets (let’s assume datasets that range from high megabytes to low gigabytes in size in this scenario), and there is no need to use any type of elastic compute technology. This typically equates to circa 60–85% of the usual use cases.
- The ETL pipelines are very complex, operate over very large datasets (high gigabyte and beyond) and require the processing technology to be able scale in order to compute results in an effective time. These usually account for the remaining 15–40% of the use cases.
The first scenario is by far the most common one, and this is a good thing. The fact that most ETL pipeline tasks are typically „simple“ means that you might be able to avoid using technologies that would quickly lock you in to a particular storage and/or compute technology. Scenario 2 is usually when things get trickier (and more fun!).
In a scenario where you need the underlying technology to scale up with the datasets, you need to start making some choices and compromising on technology. Fortunately these days there are a lot of tools on this spectrum, and cloud providers typically focus on maintaining and investing in a small number of them. For GCP, you might consider using DataFlow, DataProc and BigQuery to process your data while on AWS you can consider Athena, EMR and Redshift.
Regardless of the tool selection or the cloud provider, there will always be a need to orchestrate how these processes glue together to implement your data pipelines. This is where a tool like Pentaho Data Integration can help regardless of the technological choice.
How can a tool like Pentaho Data Integration help?
For anyone not aware, Pentaho Data Integration (PDI) by Hitachi Vantara is an open-source ETL tool that you can use to implement all your common ETL tasks. Fortunately, it can also help with cloud execution and orchestration scenarios with some of its internal features:
- It has its own transformation engine that you can use to process data independently of the cloud provider.
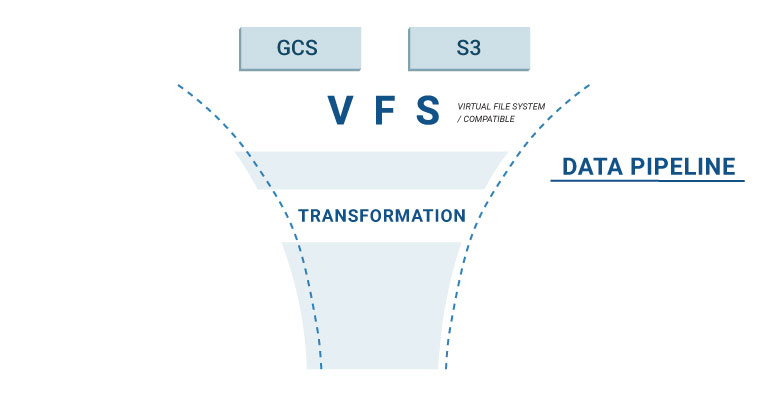
- It can abstract the underlying storage system using the Virtual File System (VFS) concept.
- It can interact with other external technologies, such as Google BigQuery or Redshift, for example, in order to orchestrate other parts of the processing pipeline.
So, how can you do this?
Abstracting the underlying storage layer
PDI offers a very useful VFS functionality which is built on top of the Apache VFS project in order to abstract file system access. What this means is that for every process that requires reading and/or writing into a filesystem, you can implement it without having to think about the type of filesystem that is being used; whether it is a local filesystem, a remote SFTP server, Google Cloud Storage or S3, ETL transformations correctly implemented using the VFS will seamlessly work with all of them. How does this work?
Very easy! The VFS notation requires you to specify a prefix to your filesystem that will enable you to specify a path such as:
filesystem://path/to/file.txt
Which means that if, in your ETL pipeline you need to access a file or files that exist in a path denominated „/input-data/sales/“ you can use the following functionality to express the path:
file:///input-data/sales/
s3://bucket-name/input-data/sales/
gs://bucket-name/input-data/sales/
In a nutshell, what this means is that you can write highly portable code that can operate under a filesystem independently of the storage type! Great, so what else can we do to maintain some portability?
An external portable engine to execute ETL on
As we stated previously, PDI bundles its own execution engine, and since it’s based on Java, you can run it wherever the JVM runs, which means that you can implement your ETL processes without having to think about the underlying technology – which makes it highly portable across environments. You can code it once and deploy it everywhere the engine runs.
What this means is that for simple ETL pipelines, you can achieve a very portable design with PDI which will allow you to move across environments very easily, let’s see an example:
- You start by designing and testing your ETL on premise with your own servers and local filesystem, where PDI is hosted in its own VM or dedicated server.
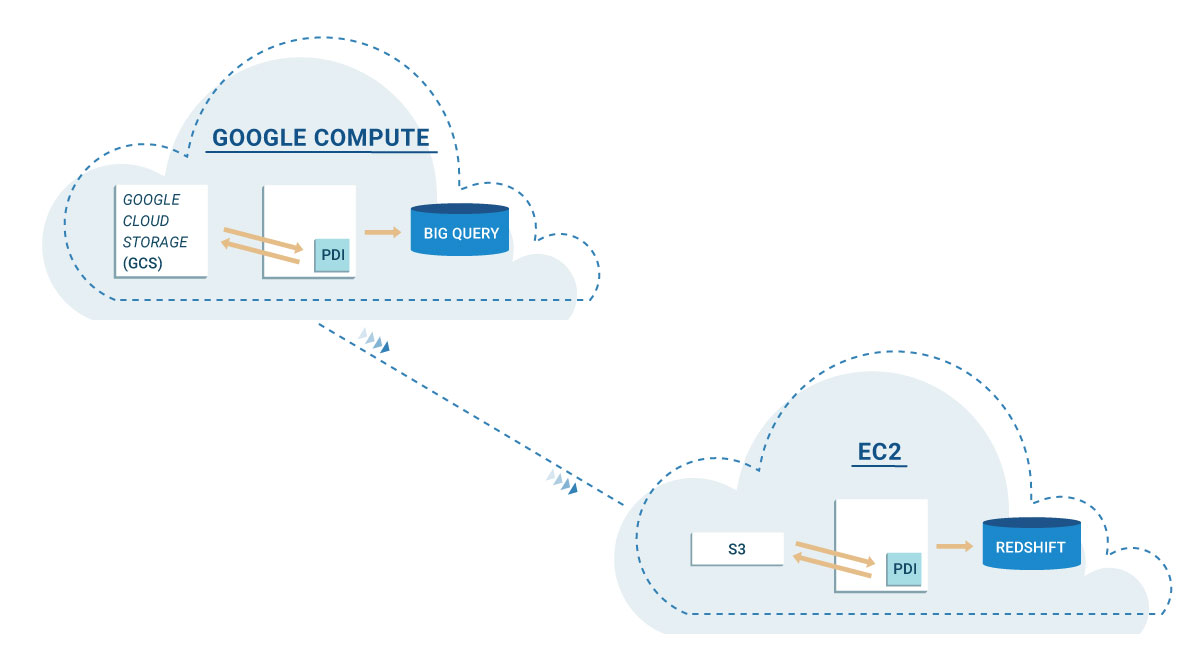
- You decide you want to move to AWS: you parametrise the ETL in order to use AWS S3 as the file system and deploy PDI in its own EC2 instance.
- You are required to use Google Cloud Platform because you need it to operate in a very specific region: you parametrise the ETL to use GCS as the filesystem and deploy PDI in its own Google Compute instance.
Of course, this is still a very limited view of what you can achieve in a cloud platform, but it does give you 100% portability and ease of transportation of your ETL environment. For more complex scenarios, PDI gives you options to either scale out or connect to other external tools:
- You can use a farm of Carte servers to horizontally scale your execution, either to split or cluster the processing
- You can implement your data transformations using Map/Reduce
- You can use AEL to scale out your data processing using Spark
- You can connect to tools like Google BigQuery and/or Redshift after loading the data to do further processing
These more complex scenarios add in the additional fact that you must be able to easily orchestrate the pipeline to avoid getting into an implementation tangle.
Orchestrating the data pipeline
Although, as stated in the beginning of this blog post, there are typically two types of ETL pipeline scenarios, in reality they usually come together to form the overall ETL processing pipeline. In the scenario where (some) portability between cloud providers is desired, it is crucial that you have a tool at your disposal that is highly flexible and parameterisable in order to be able to dynamically adapt to the execution requirements.
For example, if you have your AWS implementation utilizing S3 and Redshift and want to move to GCP:
- The code for file manipulation and processing that purely utilizes S3 is 100% portable if implemented correctly using the VFS capabilities.
- The code that loads and operates Redshift will most likely not be portable, but it can be implemented in a way that can be substituted by a Google BigQuery implementation that uses the same input file layouts and table structure to achieve the same functionality.
Of course this situation will require you to maintain code modules that are specific to each cloud provider, but at least you can compartmentalise and encapsulate this functionality in a way that you can easily swap them if required. With PDI, the job orchestration functionality allows you to not only parameterise settings but also the actual execution pipeline, which would make this situation extremely easy to implement.
Conclusion
We hope this blog post was enlightening on how you can design your ETL pipelines and maintain some portability across cloud vendors. Tools like Pentaho Data Integration make your life much easier in achieving this and, we hear that the upcoming versions of PDI will further ease portability with some cool new features!










