Big Data
Solutions
We unlock Big Data value and empower real-time decisions
We believe the Big Data challenge is the ability to manage large volumes of data, generated at high speeds, in order to deliver valuable insights or simply by making sure data gets where it needs to.
Our secret is a multi-disciplinary team with top of the line skills in leveraging distributed data processing platforms, mixed with an agile and interactive approach and a set of power technology partners.
Looking for experts in Big Data solutions? We have a data-driven team for hire!
How can we help?




Big Data Consulting
You know your business. We know data and the trendy Big Data platforms and we strive to work with you to develop a Big Data approach that can leverage and extract value from your data.

Big Data Development
Our Big Data experts with mastery in Data platforms can help you develop NRT (near real-time) and batch data pipelines for all types of data, or lightning fast demanding operational scenarios.

Big Data Operations
We help customers define, install, configure, manage and tune a distributed data environment. We can help you define and implement a DevOps/DataOps strategy on top of those platforms.
Technology use cases
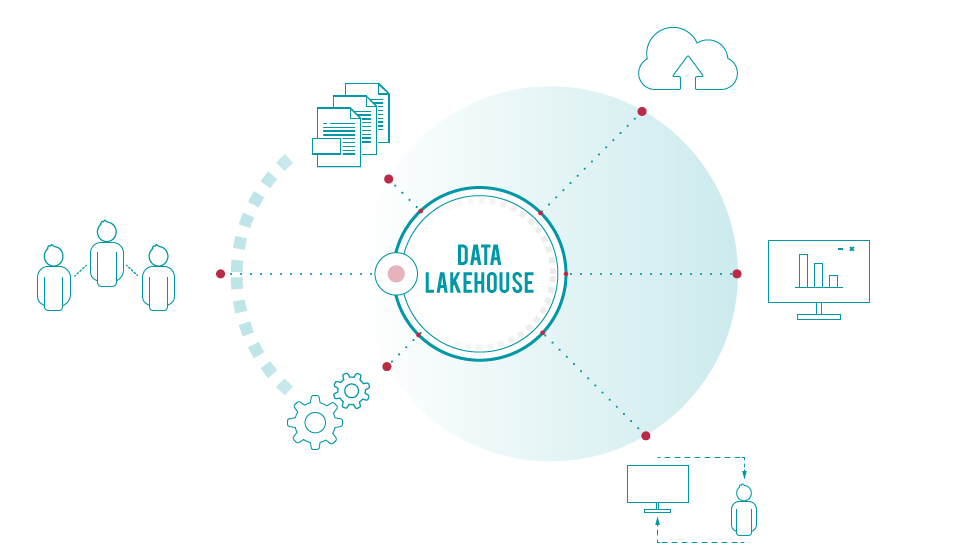
Data Lakehouse
The ability to bring to one place data coming from both outside and inside your organisation, from operational systems, sensors or social networks, with virtually no volume constraints, at varying speeds, at an affordable cost, enables you to attain a competitive edge over your competition.
This is what a Data Lakehouse approach can do for you, which brings data and compute together to enable the data-centric enterprise.
Analytics at scale
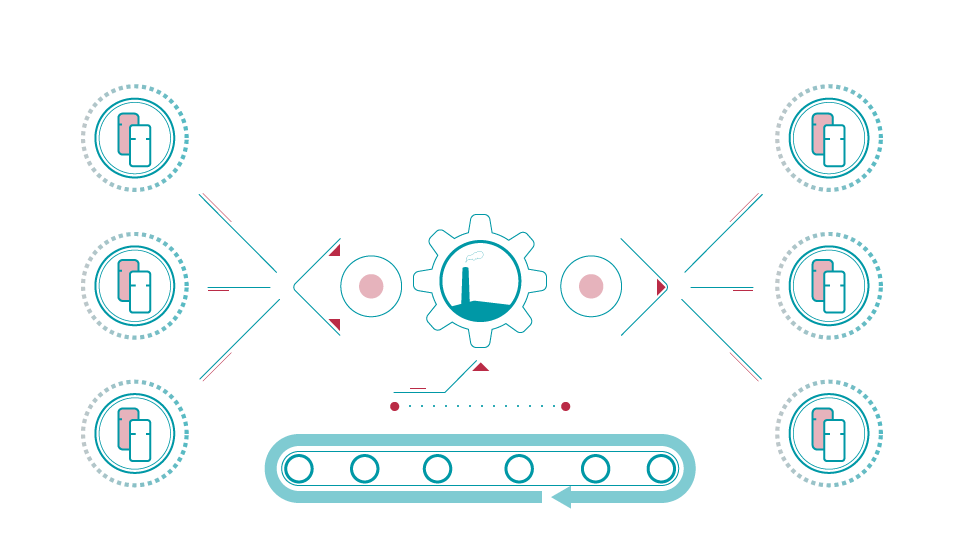
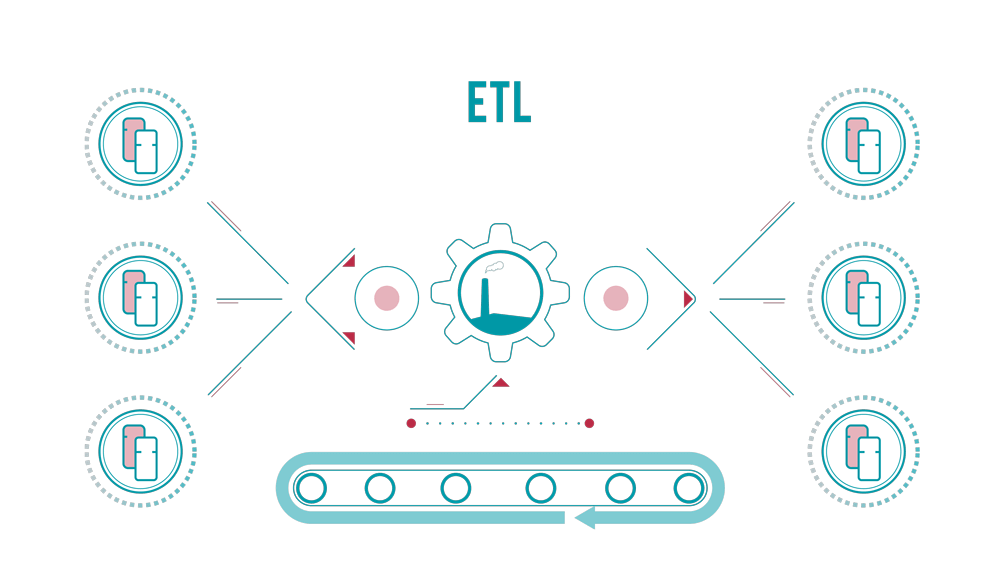
If you are like all other organisations in the world, your data processing window and needs are constantly under pressure. Data volumes and pipeline complexity are ever increasing, and your traditional ETL approach is unable to cope with the demands.
What if you could take advantage of modern data processing techniques based on distributed systems and leverage a scalable data infrastructure and processing frameworks to run your analytics jobs at a manageable cost?
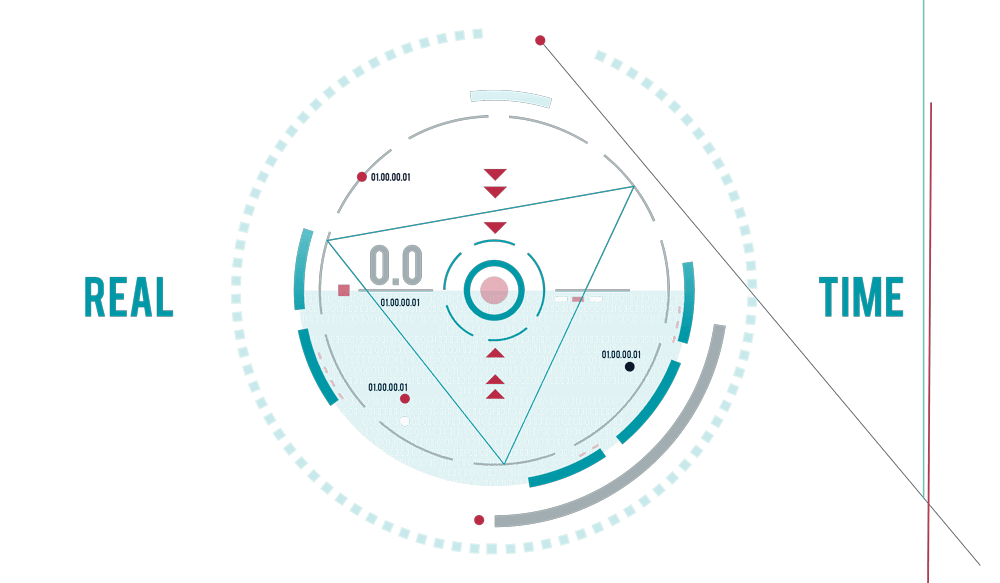
Near real-time solutions
Sometimes, you need to act on data as soon as it is produced, either through analytics, recommendation or other operational requirements.
Big Data platforms offer you the ability to build a near real-time solution for data processing.
Case studies
Cloud/Hybrid Data Strategy
Advisory and implementation of a data-centric strategy for a telco company.
Data Governance
Definition and implementation of a Data Governance tool in Big Data Platforms.
Customer 360
Implementation of 360 customer solutions across the industry.
Real-time Event Processing
Building event processing pipelines for near real-time business analytics.
Technologies & Partners





